When using RabbitMQ rascalamqplib, you may encounter the error Errorunexpected close
rabbitMQ rascal/amqplib error Error: Unexpected close troubleshooting
Missed (client) heartbeat
The first common cause is that RabbitMQ detects a heartbeat loss. When this happens, RabbitMQ will add a log entry about it and then close the connection as required by the specification.
Here's what a missing client heartbeat looks like in the RabbitMQ logs:
2017-09-26 08:04:53.596 [warning] <0.2375.628> closing AMQP connection <0.2375.628> (127.0.0.1:54720 -> 127.0.0.1:5672):
missed heartbeats from client, timeout: 8s
For clients whose I/O operations are not concurrent with the consumer operation (which I believe is the case here), RabbitMQ will detect a missed client heartbeat if the consumer operation takes longer than the heartbeat timeout. Disabling heartbeat may help, but I don't recommend it.
If you disable heartbeats, make sure your kernel is configured to use sensible TCP keepalive settings, which is not the case by default on all popular Linux distributions
rabbit heartbeat
Check the rabbitmq log/var/log/rabbitmq/rabbit@ecmaster.log
closing AMQP connection <0.4893.0> (127.0.0.1:58310 -> 127.0.0.1:5672):
missed heartbeats from client, timeout: 10s
The value of hearbeats can be viewed in the connection interface of the web console.
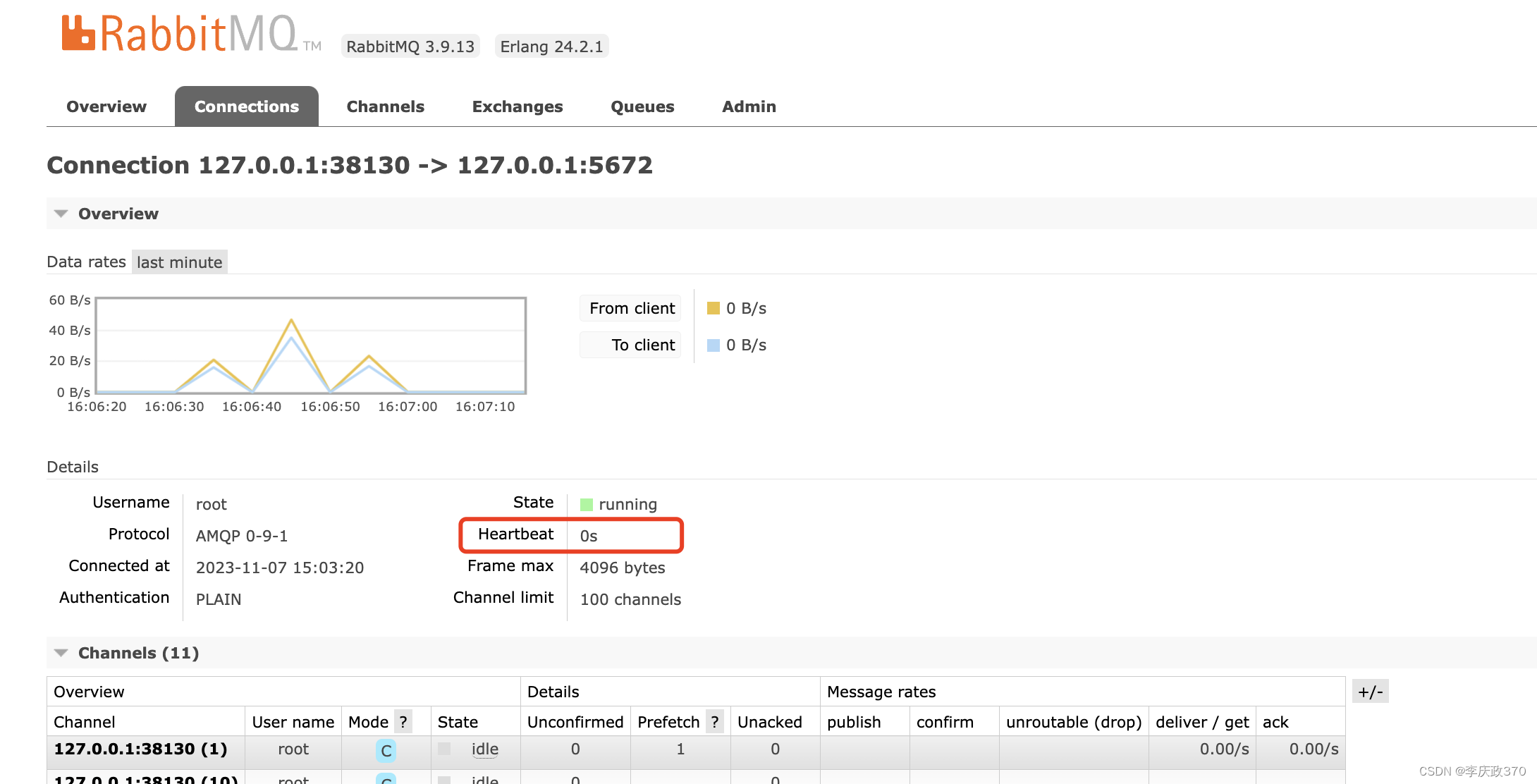
The client negotiates the heartbeat check time with rabbitqm-server (the server defaults to 60s).
If either value is 0, the larger of the two is used, otherwise the smaller of the two is used.
A value of zero means the peer recommends disabling heartbeats entirely. To disable heartbeat, both peers must opt-in and use the value 0. It is strongly recommended not to do this unless the environment is known to use TCP keepalives on each host (see Item 5). It is also strongly recommended not to use very low values.
Rascal can adjust the connection.options.heartbeat in the configuration file to configure the heartbeat time. The default is 10.
rabbitmq-server can be found in /etc/rabbitmq/rabbitmq.conf (create it if it does not exist). Adjust the heartbeat configuration item heartbeat = 60. After modification, restart systemctl restart rabbitmq-server.service.
Intermediary closes “inactive” TCP connections
Second common cause: The TCP connection was closed by an intermediary (such as a proxy or load balancer).
If you see the following in your RabbitMQ logs
2017-09-26 08:08:39.659 [warning] <0.23042.628> closing AMQP connection <0.23042.628> (127.0.0.1:54792 -> 127.0.0.1:5672, vhost: '/', user: 'guest '):
client unexpectedly closed TCP connection
This means that the client's TCP connection was closed before the AMQP 0-9-1 (that client's) connection. Sometimes this is harmless, meaning the application does not close the connection before terminating. Not great, but no functional drawbacks. Such log entries may also indicate that the client application process failed (unrelated to this thread) or, quite commonly, that the proxy closed the connection. Proxies and load balancers have TCP connection inactivity timeouts, mentioned in the Heartbeat Guide). Their length is usually 30 seconds to 5 m.
While heartbeats and TCP keepalives are not designed to solve an unfortunate load balancer or proxy setup, they do exactly that by generating regular network traffic.
Other connection lifecycle log entries
The entries below are not necessarily related to failed socket writes, but they are worth explaining,
Because they are very useful (and can be misunderstood) when troubleshooting connection-related issues.
If you only see the following in the RabbitMQ logs:
closing AMQP connection <0.13219.456> (153.xxx:56468 -> 185.xxx:5672)
(There are no mentions or heartbeats, unexpectedly closed TCP connections, connection errors, or any timeout socket writes on the RabbitMQ side), which means the client connection was closed cleanly and successfully, and was initiated by the application.
{writer,send_failed,{error,timeout}}
Meaning RabbitMQ tried to write to the socket, but the operation timed out. If you see this while the client writes are failing, it means the connection failed, but heartbeats or TCP keepalives were not enabled and it was not detected faster.
Other possible reasons? TCP connections may fail.
In most other cases, a failed socket write is a failed socket write. Network connections may fail or experience degraded performance. There is no way this client or RabbitMQ can avoid this. This is why heartbeats were introduced in messaging protocols such as AMQP 0-9-1, STOMP, MQTT, etc., and in this client, heartbeats did not serve its purpose well.
An alternative: TCP Keepalive
TCP keepalive can be used as an alternative. They don't guarantee that your connection will never fail - the goal is still to detect such connections faster - so you may still see failed socket writes.
TCP KeepAlive
TCP includes a mechanism similar to the heartbeat (aka keepalive) in the messaging protocol described above: TCP keepalive. Because the default values are insufficient, TCP keepalives cannot be assumed to be suitable for messaging protocols. However, with appropriate tuning, they can serve as an additional defense mechanism in environments where applications cannot be expected to enable heartbeats or use sensible values.
In some rare cases where heartbeats alone are not sufficient (for example, when the connection involved uses a protocol that does not have some heartbeat mechanism), TCP keepalives must be configured to use a considerably lower timeout value.
It is also possible to use TCP keepalives in place of heartbeats by configuring TCP keepalives to lower system-specific values. In this case, the heartbeat can be deactivated. The main benefit of this approach is that all TCP connections on the computer will use the same value, regardless of the protocol and client library used.
The TCP protocol uses the KeepAlive mechanism to determine whether the application is offline or there is indeed no data transmission. After a period of time, TCP automatically sends a message with empty data to the other party. If the other party responds to this message, it means that the other party is still online. The connection can continue to be maintained. If no message is returned from the other party and the connection is retried multiple times, the connection is considered lost and there is no need to maintain the connection.
KeepAlive is not enabled by default. There is no global option to enable TCP KeepAlive on Linux systems. Applications that need to enable KeepAlive must be enabled separately in the TCP socket. The Linux Kernel has three options that affect the behavior of KeepAlive:
sysctl -a|grep keepalive //View values
net.ipv4.tcpkeepalivetime = 7200
net.ipv4.tcpkeepaliveintvl = 75
net.ipv4.tcpkeepaliveprobes = 9
The unit of tcpkeepalivetime is seconds, which indicates how many seconds after the TCP connection has no data packet transmission to start the detection packet; 60
The unit of tcpkeepaliveintvl is seconds, which represents the time interval between the previous detection message and the next detection message.
tcpkeepaliveprobes indicates the number of probes.
sysctl -w net.ipv4.tcp_keepalive_time=60 Adjust KeepAlive parameters
sysctl -w net.ipv4.tcp_keepalive_intvl=10
sysctl -w net.ipv4.tcp_keepalive_probes=6
Connection restored
Automatic connection recovery is a feature supported by several RabbitMQ clients over the years, such as the Java client and Bunny. This is considered an issue that the RabbitMQ team has solved,
At least in terms of the general approach when restoring a topology and the sequence of recovery steps. Consider following the steps outlined in these customer documents rather than reinventing your own.