Three ways to convert word to PDF in Java and deal with the format that is garbled after downloading on the server
Three ways to convert word to PDF in Java and deal with the format that is garbled after downloading on the server
This is because my business needs to convert the previously exported word document into a PDF file, and then download the page preview. It was not me who exported the word document before, so in order not to affect the business, I just converted it to PDF when outputting the stream. At that time, there was no problem with the local call and everything was normal. Later, when I released the test environment and used it, I discovered that the PDF file was exported. The content is garbled and no Chinese characters are displayed.
Here is a record of the problems encountered and solutions:
1: Solve the problem of Chinese characters not being displayed and garbled characters being processed
I am using POI for conversion here, directly converting word to PDF, and the conversion method will be listed later.
The converted PDF looked like this:

There are many Chinese instructions in the normal format. Here's how to handle it:
At that time, I thought that the server did not support Chinese, so I searched around on Baidu, and sure enough, I started adding Chinese fonts:
The font directory on the Linux server is: 1 under /user/share/fonts
: Create your own folder fonts under /user/share/fonts, here is my-fonts.
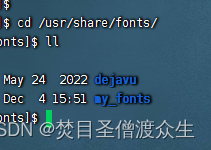
If you can’t find it here, you can use the command fc-listto check if there is one. If not or the command is not available, then you need First install the basic fonts: use the command: yum -y install fontconfig, after completion you will see /user/share/fonts
2: Find the fonts in Windows and upload the fonts to my-fonts.
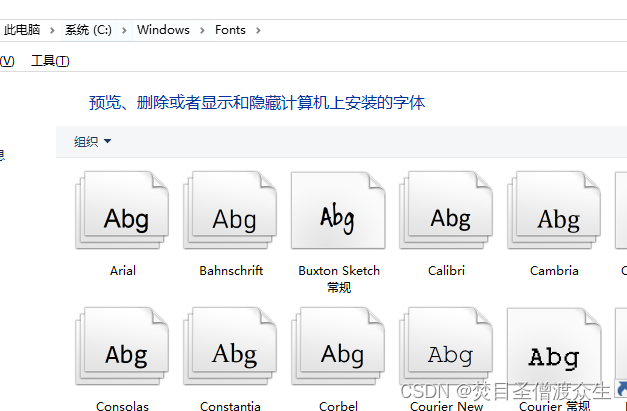
There are many fonts in it. What we need are Chinese fonts. You can selectively upload them. Select the Chinese fonts you need to upload, such as Song Dynasty, and you need to match your file template. Just make sure the fonts are the same. Upload to my-fonts folder
3: Installation
Then create a scale file based on the fonts in the current directory,
switch to the my-fonts directory and execute the command: mkfontscale
If prompted mkfontscale command not found, runyum install mkfontscale
Then create the dir file: mkfontdir
use the command: vi /etc/fonts/fonts.confmodify the configuration file, add: <dir>/usr/share/fonts/my-fonts</dir>
After adding:
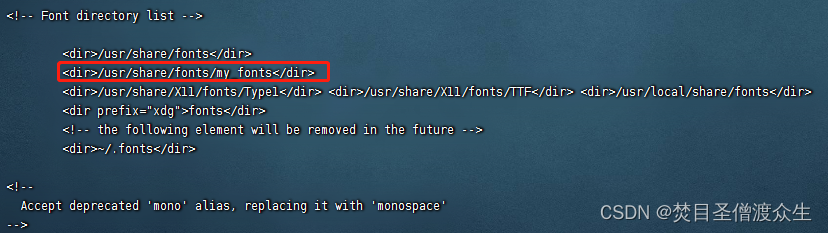
Then run: fc-cache
fc-list#View font list
4: Grant permissions
chmod 777 /usr/share/fonts/my-fonts
chmod 755 /usr/share/fonts/my-fonts/*
Use the command to view: fc-list :lang=zh
2: Several ways to convert Word to PDF
1: Use POI to convert word to PDF
and introduce dependencies:
<dependency>
<groupId>fr.opensagres.xdocreport</groupId>
<artifactId>fr.opensagres.poi.xwpf.converter.[pdf](/search?q=pdf)-gae</artifactId>
<version>2.0.1</version>
</dependency>
Add and modify response .docx to .pdf before closing the stream
response.setHeader("Content-Disposition", "attachment; filename=" + [java](/search?q=java).net.URLEncoder.encode("dailies-"+datetime+".pdf" , "UTF-8"));;
// to PDF
PdfOptions options = PdfOptions.create();; PdfConverter.
PdfConverter.getInstance().convert(document, outStream, options);
/ / / the following is to turn the word inside the last code, close the stream
2: Use the Document method of aspose.words to convert word to PDF
1: Download the jar package: Download the jar package
2: Place the jar package into the lib folder in the resources directory of the project:
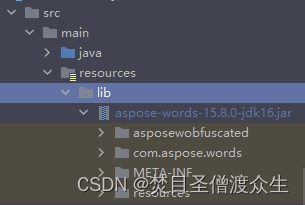
3: Convert the jar package to
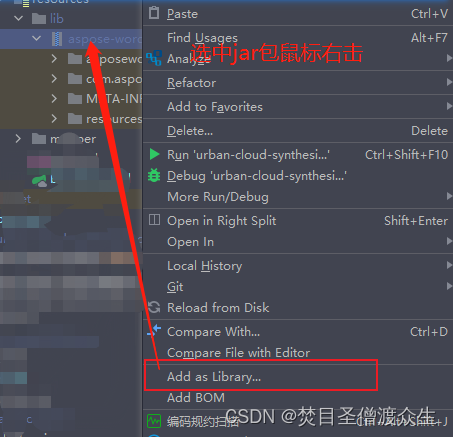
library Then the arrow in the picture above will appear and you can open it.
4: Introduce jar package dependencies:
<dependency>
<groupId>com.aspose.words</groupId>
<artifactId>aspose-words</artifactId>
<version>15.8.0</version>
<scope>system</scope>
<systemPath>${project.basedir}/src/main/resources/lib/aspose-words-15.8.0-jdk16.jar</systemPath>
</dependency>
Add to packaged dependencies:
<plugin>
<configuration>
<includeSystemScope>true</includeSystemScope>
</configuration>
</plugin>
5: Conversion
String s = "<License><Data><Products><Product>Aspose.Total for Java</Product><Product>Aspose.Words for Java</Product></Products><EditionType>Enterprise</EditionType><SubscriptionExpiry>20991231</SubscriptionExpiry><LicenseExpiry>20991231</LicenseExpiry><SerialNumber>8bfe198c-7f0c-4ef8-8ff0-acc3237bf0d7</SerialNumber></Data><Signature>sNLLKGMUdF0r8O1kKilWAGdgfs2BvJb/2Xp8p5iuDVfZXmhppo+d0Ran1P9TKdjV4ABwAgKXxJ3jcQTqE/2IRfqwnPf8itN8aFZlV3TJPYeD3yWE7IT55Gz6EijUpC7aKeoohTb4w2fpox58wWoF3SNp6sK6jDfiAUGEHYJ9pjU=</Signature></License>";
// Remove the watermark
ByteArrayInputStream is = new ByteArrayInputStream(s.getBytes());
License license = new License();
License.setLicense(is); //Transform the XWPFDList into an XWPFDList.
// XWPFDocument converted to InputStream
ByteArrayOutputStream b = new ByteArrayOutputStream();; //Here document = new ByteArrayOutputStream(); license.setLicense(is)
// here document = XWPFDocument document, in the following word conversion
document.write(b);
InputStream inputStream = new ByteArrayInputStream(b.toByteArray());;
//The introduction of Document here is
//import com.aspose.words.
//import com.aspose.words.License; //import com.aspose.words.
//import com.aspose.words.SaveFormat; //import com.aspose.words.
Document doc = new Document(inputStream); //import com.aspose.words.
Document.save(outStream, SaveFormat.PDF); doc.save(outStream, SaveFormat.PDF); //import com.aspose.words.
SaveFormat.PDF); b.close();
inputStream.close();
// the following and then turn the word inside the last code, close the stream
3: Use documents4j to convert word to PDF
1: Introduce dependencies:
<! -- word to pdf via documents4j -->
<dependency>
<groupId>com.documents4j</groupId>
<artifactId>documents4j-local</artifactId>
<version>1.0.3</version>
</dependency>
<dependency>
<groupId>com.documents4j</groupId>
<artifactId>documents4j-transformer-msoffice-word</artifactId>
<version>1.0.3</version>
</dependency>
2: Conversion is as follows:
//convert XWPFDocument to InputStream
ByteArrayOutputStream b = new ByteArrayOutputStream();
// here document = XWPFDocument document, in the following word conversion
document.write(b);
InputStream docxInputStream = new ByteArrayInputStream(b.toByteArray());
// The following introductory class is:
//import com.documents4j.api.DocumentType; //import com.documents4j.api.
//import com.documents4j.api.IConverter; //import com.documents4j.api.
//import com.documents4j.job.LocalConverter; //import com.documents4j.api.
IConverter converter = LocalConverter.builder().build();
boolean execute = converter.convert(docxInputStream)
.as(DocumentType.DOCX)
.to(outStream)
.as(DocumentType.PDF).schedule().get();
b.close();
docxInputStream.close();
3: The previous conversion method of word is recorded as follows
1: Make a word template and write the value to be converted as ${variable name}.

2: Conversion
//address of the template file
String filePath = "/usr/local/data/template.docx";
//Map to store the value to be replaced
Map<String, Object> map = new HashMap<>();
map.put("${date}", date);
map.put("${datetime}", datetime);
//write
try {
// Replace the keyword in the Set collection.
Set<String> set = map.keySet(); // Read the template document.
// Read the template document
XWPFDocument document = new XWPFDocument(new FileInputStream(filePath )); // Read the template document.
/**
* Replace the specified text in a paragraph
*/
// Reads a paragraph from a document with a carriage return.
// The same paragraph will be separated into multiple objects by symbols such as ":".
Iterator<XWPFParagraph> itPara = document.getParagraphsIterator(); // Read the document's paragraphs.
while (itPara.hasNext()) {
// Get the text of the current paragraph in the document
XWPFParagraph paragraph = (XWPFParagraph) itPara.next(); } }
List<XWPFRun> run = paragraph.getRuns(); // Iterate over the paragraph text objects.
// Iterate over the paragraph text objects
for (int i = 0; i < run.size(); i++) {
// Get the paragraph object
if (run.get(i) == null) { // paragraph.get(i) == null) { // skip if paragraph is empty
continue; }
}
String sectionItem = run.get(i).getText(run.get(i).getTextPosition()); // paragraph content
// System.out.println("Before replacing === "+sectionItem); // Iterate through the custom form keywords.
// Iterate over the custom form keywords to replace the content in the Word document
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
// the current keyword
String key = iterator.next(); // Replace the content.
// Replace the content
sectionItem = sectionItem.replace(key, String.valueOf(map.get(key)));
}
//System.out.println(sectionItem);
run.get(i).setText(sectionItem, 0);
}
}
/**
* Replace the specified text in the table
*/
// Get all the tables in the document, each table is an element
Iterator<XWPFTable> itTable = document.getTablesIterator();
while (itTable.hasNext()) {
XWPFTable table = (XWPFTable) itTable.next(); // get table contents
int count = table.getNumberOfRows(); // the number of rows of the table
// Iterate through the table rows of the object
for (int i = 0; i < count; i++) {
XWPFTableRow row = table.getRow(i); //the contents of each row of the table
List<XWPFTableCell> cells = row.getTableCells(); //the content of each cell
// Iterate through the form of each row of the cell object
for (int j = 0; j < cells.size(); j++) {
XWPFTableCell cell = cells.get(j); //get the content of each cell
List<XWPFParagraph> paragraphs = cell.getParagraphs(); //get all paragraphs in cell
for (XWPFParagraph paragraph : paragraphs) {
//Get the content of the paragraphs
List<XWPFRun> run = paragraph.getRuns(); // Iterate over the paragraph text objects.
// Iterate through the paragraph text objects
for (int o = 0; o < run.size(); o++) {
// Get the paragraph object
if (run.get(o) == null || run.get(o).equals("")) {
run.get(o).equals("")) { continue;
}
String sectionItem = run.get(o).getText(run.get(o).getTextPosition()); // get the content of the paragraph
if (sectionItem == null || sectionItem.equals("")) { // Skip if paragraph is empty
continue; }
}
// Iterate over the custom form keywords and replace the contents of the table cells in the Word document.
for (String key : map.keySet()) {
// Replace the content
sectionItem = sectionItem.replace(key, String.valueOf(map.get(key)));
run.get(o).setText(sectionItem, 0);
}
}
}
}
}
}
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd"); String datetime = sdf.format(new Date());
String datetime = sdf.format(new Date());
String datetime = sdf.format(new Date()); response.setStatus(200);
response.setCharacterEncoding("utf8");
OutputStream outStream = response.getOutputStream();
//Here will be inserted into the code converted to PDF
outStream.close(); document.close()
document.close();
} catch (Exception e) {
e.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } }
}
The above is the code for converting word in other people's previous business scenarios.