RabbitMq related in-depth operations
RabbitMq related in-depth operations
Article directory
- Idempotence
- priority queue
- lazy queue
- mirror queue
- message retry
- Integrated use of SpringBoot
- unacked
-
- common problem
尚硅谷笔记整理
Idempotence
The results of one request or multiple requests initiated by the user for the same operation are consistent, and there will be no side effects caused by multiple clicks.
Problems arise :
When the consumer consumes the message in MQ, MQ has already sent the message to the consumer. When the consumer returns ack to MQ, the network is interrupted, so MQ does not receive the confirmation information, and the message will be resent to others. consumer, or send it to the consumer again after the network is reconnected, but in fact the consumer has successfully consumed the message, causing the consumer to consume duplicate messages.
Solutions
Generally, a global ID is used or a unique identifier is written, such as a timestamp or UUID, or an order consumer consumes messages in MQ. You can also use the ID of MQ to judge, or you can generate a globally unique ID according to your own rules.每次消费消息时用该 id 先判断该消息是否已消费过
There are two mainstream idempotent operations in the industry:
- Unique ID + fingerprint code mechanism, using database primary key to deduplicate
fingerprint codes: some of our rules or timestamps plus unique information codes given by other services are not necessarily generated by our system, they are basically generated by our business rules It is spliced together, but the uniqueness must be ensured, and then the query statement is used to determine whether the ID exists in the database. The advantage is that it is simple to implement, just one splice, and then the query determines whether it is repeated; the disadvantage is that in high concurrency, if it is a single database There will be a writing performance bottleneck. Of course, you can also use sub-database and sub-table to improve performance, but it is not our most recommended method. - Use the atomicity of redis to implement
the setnx command using redis, which is naturally idempotent. So as to achieve no repeated consumption
priority queue
Some messages must be processed with priority. In the past, our back-end system used redis to store regular polling. Everyone knows that redis can only use List to make a simple message queue, and cannot implement a priority scenario. Therefore, when the order volume is large, RabbitMQ is used for transformation and optimization. If it is found that the order is from a large customer, it will be given a relatively high priority, otherwise it will be the default priority.
How to add
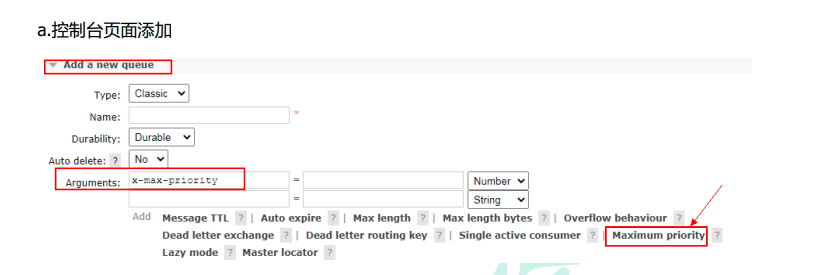
Add priority to code in queue
Map<String, Object> params = new HashMap();
params.put("x-max-priority", 10);
channel.queueDeclare("hello", true, false, false, params);

Add priority to code in message
AMQP.BasicProperties properties =
new AMQP.BasicProperties().builder().priority(5).build();
Note:
The following things need to be done to achieve priority for the queue: the queue needs to be set as a priority queue, the message needs to set the priority of the message, and the consumer needs to wait for the message to be sent to the queue before consuming it. Because, in this way, there is Opportunity to sort messages
Actual combat
message producer
public class Producer {
private static final String QUEUE_NAME="hello";
public static void main(String[] args) throws Exception {
try (Channel channel = RabbitMqUtils.getChannel();) {
//给消息赋予一个 priority 属性
AMQP.BasicProperties properties = new
AMQP.BasicProperties().builder().priority(5).build();
for (int i = 1; i <11; i++) {
String message = "info"+i;
if(i==5){
channel.basicPublish("", QUEUE_NAME, properties, message.getBytes());
}else{
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
}
System.out.println("发送消息完成:" + message);
}
}
}
}

message consumer
public class Consumer {
private static final String QUEUE_NAME="hello";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMqUtils.getChannel();
//设置队列的最大优先级 最大可以设置到 255 官网推荐 1-10 如果设置太高比较吃内存和 CPU
Map<String, Object> params = new HashMap();
params.put("x-max-priority", 10);
channel.queueDeclare(QUEUE_NAME, true, false, false, params);
System.out.println("消费者启动等待消费......");
DeliverCallback deliverCallback=(consumerTag, delivery)->{
String receivedMessage = new String(delivery.getBody());
System.out.println("接收到消息:"+receivedMessage);
};
channel.basicConsume(QUEUE_NAME,true,deliverCallback,(consumerTag)->{
System.out.println("消费者无法消费消息时调用,如队列被删除");
});
}
}

lazy queue
RabbitMQ introduced the concept of lazy queue starting from version 3.6.0. The lazy queue will store messages on disk as much as possible, and will only be loaded into memory when the consumer consumes the corresponding message. One of its important design goals is to be able to support longer queues, that is, to support more message storage. Lazy queues are necessary when consumers are unable to consume messages for a long time due to various reasons (such as consumers going offline, downtime, or shutting down due to maintenance, etc.).
By default, when a producer sends a message to RabbitMQ, the message in the queue will be stored in memory as much as possible, so that the message can be sent to the consumer faster. Even persistent messages retain a copy in memory while being written to disk. When RabbitMQ needs to release memory, it will page the messages in the memory to the disk. This operation will take a long time and will also block the queue operation, making it impossible to receive new messages. Although the developers of RabbitMQ have been upgrading related algorithms, the results are still not ideal, especially when the message volume is particularly large.
RabbitMq queue has two modes: default and lazy. The default mode is default, and no changes are required for versions prior to 3.6.0. The lazy mode is the mode of the lazy queue. It can be set in the parameters when calling the channel.queueDeclare method, or it can be set through the Policy. If a queue is set using both methods at the same time, the Policy method has higher priority.
If you want to change the mode of an existing queue through declaration, you can only delete the queue first and then re-declare a new one.
在队列声明的时候可以通过“x-queue-mode”参数来设置队列的模式,取值为“default”和“lazy”。下面示
例中演示了一个惰性队列的声明细节:
Map<String, Object> args = new HashMap<String, Object>();
args.put("x-queue-mode", "lazy");
channel.queueDeclare("myqueue", false, false, false, args);
内存开销对比 : 在发送 1 百万条消息,每条消息大概占 1KB 的情况下,普通队列占用内存是 1.2GB,而惰性队列仅仅占用 1.5MB
镜像队列
如果 RabbitMQ 集群中只有一个 Broker 节点,那么该节点的失效将导致整体服务的临时性不可用,并且也可能会导致消息的丢失。可以将所有消息都设置为持久化,并且对应队列的durable属性也设置为true,但是这样仍然无法避免由于缓存导致的问题:因为消息在发送之后和被写入磁盘井执行刷盘动作之间存在一个短暂却会产生问题的时间窗。通过 publisherconfirm 机制能够确保客户端知道哪些消息己经存入磁盘,尽管如此,一般不希望遇到因单点故障导致的服务不可用。
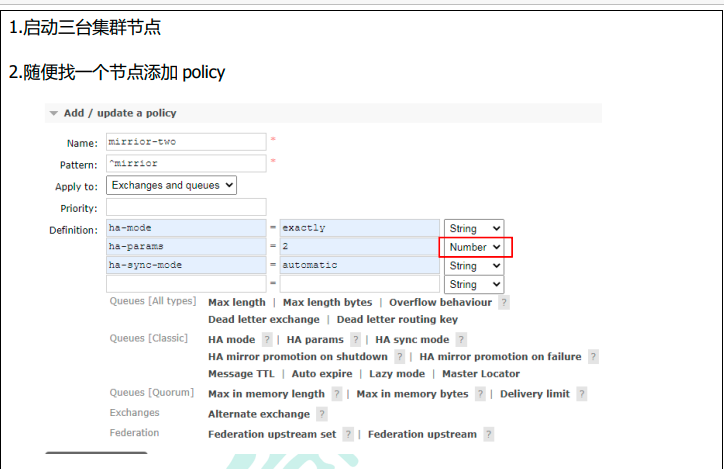

停掉 node1 之后发现 node2 成为镜像队列

消息重试
SpringBoot整合使用
消费者:
在 Spring Boot 中,我们可以使用 @RabbitListener 注解来监听 RabbitMQ 中的消息。@RabbitListener 注解会自动创建一个监听器容器,用于接收和处理消息。默认情况下,Spring Boot 使用 SimpleRabbitListenerContainerFactory 来创建监听器容器。如果我们需要自定义监听器容器,可以使用 @RabbitListenerContainerFactory 注解。
当我们使用 @RabbitListener 注解时,Spring Boot 默认会使用 SimpleRabbitListenerContainerFactory 来创建监听器容器。如果我们不需要对监听器容器进行自定义配置,可以直接在方法上添加 @RabbitListener 注解,例如:
@RabbitListener(queues = "myQueue")
public void processMessage(String message) {
// 处理消息
}
在这个示例中,我们使用 @RabbitListener 注解来监听名为 myQueue 的队列,并在 processMessage 方法中处理接收到的消息。
自定义监听器容器工厂
如果我们需要自定义监听器容器,可以使用 @RabbitListenerContainerFactory 注解来创建自定义的监听器容器工厂。以下是一个自定义监听器容器工厂的示例代码:
@Configuration
public class MyRabbitListenerContainerFactory {
@Bean(name = "myListener")
public MessageListenerAdapter myListener() {
return new MessageListenerAdapter(new MyMessageListener());
}
@Bean
public SimpleMessageListenerContainer myContainer(ConnectionFactory connectionFactory, @Qualifier("myListener") MessageListenerAdapter listenerAdapter) {
SimpleMessageListenerContainer container = new SimpleMessageListenerContainer();
container.setConnectionFactory(connectionFactory);
container.setQueueNames("myQueue");
container.setMessageListener(listenerAdapter);
container.setAcknowledgeMode(AcknowledgeMode.AUTO);
container.setConcurrency("3-10");
return container;
}
@Bean(name = "myFactory")// 定义一个名为myFactory的SimpleRabbitListenerContainerFactory
public SimpleRabbitListenerContainerFactory myFactory(ConnectionFactory connectionFactory) {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
factory.setConnectionFactory(connectionFactory);
factory.setConcurrentConsumers(3);
factory.setMaxConcurrentConsumers(10);
factory.setAcknowledgeMode(AcknowledgeMode.AUTO);
return factory;
}
}

这个示例中,我们自定义创建一个名为 myFactory 的自定义监听器容器工厂。我们在 myFactory 中设置了一些监听器容器的属性,例如线程池大小、消息确认机制等。
@RabbitListenerContainerFactory 注解是一个用于创建 RabbitMQ 监听器容器工厂的注解。它可以用于自定义监听器容器的配置,例如线程池大小、消息确认机制、消息转换器等。
@RabbitListenerContainerFactory 注解
SimpleMessageListenerContainer用法
unacked
RabbitMQ中的unacked表示未被ACK确认的消息数,如果大量堆积可能会导致消息积压和系统负荷过大(MQ会一直重复推送unacked消息至消费者)。造成unacked大量堆积的原因可能��有很多,例如消费者处理消息的速度过慢、消费者不及时ACK确认消息、消息处理出现异常等等。
针对这种情况,可以考虑以下几点解决方案:
- 消费者处理消息的速度过慢时,可以增加消费者数量或者优化消费者代码,提高消息处理的效率。
- 消费者不及时ACK确认消息时,可以设置ACK超时时间或者手动ACK确认,避免消息长时间处于unacked状态。
- 对于消息处理出现异常的情况,可以在消费者代码中加入异常处理机制,避免消息一直处于unacked状态。
- 调整RabbitMQ服务器的配置参数,例如增加消息队列的大小、调整消息的过期时间等等,优化系统性能。
消息不会ack,在Queues中一直处于Unacked状态,直到关闭控制台程序,它才会自动将所有的Unacked的消息全部切换成Ready(虽然不知道它是怎么实现的),从而保证,下一次重启消费端时可继续尝试消费那些"失败"的消息。
那么问题来了,假如我实际业务中,消费端不重启,那么那些Unacked的消息就不会变成Ready状态,就得不到重新处理了,我应该怎么处理这些Unacked的消息?
是不是应该在业务执行失败时,把这条消息存储到另一个队列Q2(专门处理业务失败的消息)同时ack当前队列(确保该消息不同时存在于当前队列和Q2队列,但是这里无法保证)。
若消息未被 ACK 则会发送给下一个消费者,如果某个服务忘记 ACK ,RabbitMQ 会认为该服务的处理能力有限,不会再发送数据给它
总之,解决unacked大量堆积的问题需要综合考虑多个方面,从消费者、消息队列、系统配置等多个方面入手,找到问题的根源并采取合适的措施。
RabbitMQ提供了一种QOS(服务质量保证)功能,即在开启手动确认消息的前提下,限制信道上的消费者所�能保持的最大未确认的数量。可以通过设置PrefetchCount实现。
常见问题
RabbitMQ 是一个开源的消息队列中间件,常用于在分布式系统中进行消息传递。以下是一些 RabbitMQ 常见问题:
- 什么是 RabbitMQ? RabbitMQ 是一个消息队列中间件,它实现了 AMQP(Advanced Message Queuing Protocol)协议,并提供了可靠的消息传递机制。
- RabbitMQ 的主要特点是什么? RabbitMQ 的主要特点包括高度可靠性、灵活的路由机制、扩展性强、支持多种消息协议和模式、多种编程语言支持等。
- 如何安装和配置 RabbitMQ? 你可以从 RabbitMQ 官方网站下载适合你操作系统的安装包,并按照官方文档进行安装和配置。
- RabbitMQ 的主要组件是什么? RabbitMQ 的主要组件包括生产者(Producer)、消费者(Consumer)、交换机(Exchange)和队列(Queue)。
- 如何发送和接收消息? 生产者可以将消息发送到交换机,交换机根据指定的路由规则将消息路由到队列中,然后消费者可以从队列中接收消息进行处理。
- RabbitMQ 支持哪些消息模式? RabbitMQ 支持多种消息模式,包括点对点模式、发布/订阅模式、主题模式等,可以根据需求选择合适的模式。
- RabbitMQ 如何处理消息丢失和重复消费的问题? RabbitMQ 提供了消息持久化机制,可以确保消息在发送和接收过程中的可靠性。此外,使用消息确认机制和幂等性操作可以避免消息重复消费的问题。
- 如何监控和管理 RabbitMQ? RabbitMQ 提供了可�视化的管理界面,在浏览器中访问管理界面可以查看和管理队列、交换机、连接等信息。此外,还可以使用 RabbitMQ 提供的 API 进行监控和管理。