Python crawler practice - Douyin
Python crawler practice - Douyin
Table of contents
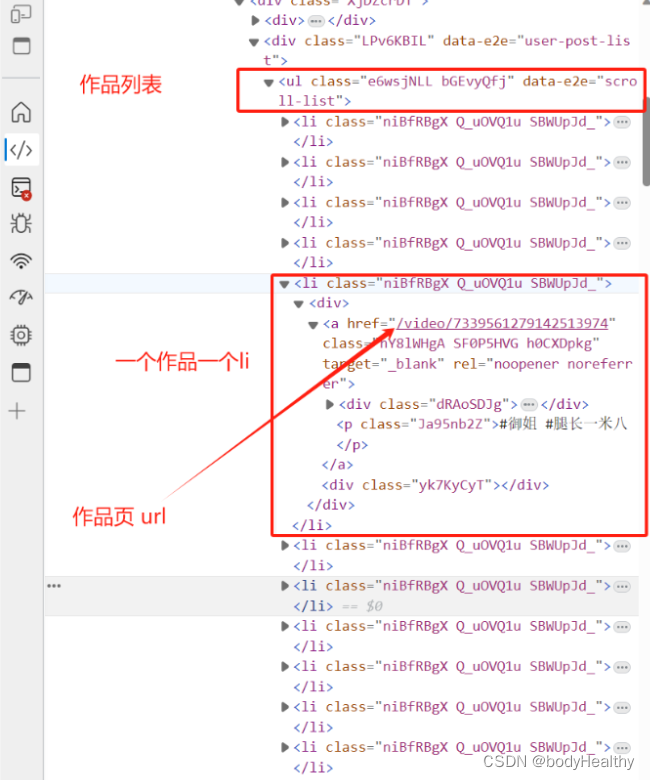
1. Analyze the tag structure of the home page’s work list
2. Before entering the work page, determine whether the work is a video work or a graphic work.
3. Enter the video works page and obtain the video
4. Enter the graphic works page to obtain pictures
5. Complete reference code
6. A way to obtain all works
This article mainly uses selenium.webdriver ( Firefox ), BeautifulSoup and other related libraries to conduct web crawling exercises in the centos system without logging in. For learning and communication purposes only.
Install and configure driver reference:
[1]: [Best practices for using Python+Selenium in Linux without graphical interface environment - Zhihu](https://zhuanlan.zhihu.com/p/653237868 "Best practices for using Python+Selenium in Linux without graphical interface environment - Zhihu")
[2]: How to solve the error 'chromedriver' executable needs to be in PATH - Zhihu
1. Analyze the tag structure of the home page’s work list
# webdriver initialization
driver = webdriver.Firefox(options=firefox_options)
# Set the page load timeout to 6 seconds
driver.set_page_load_timeout(6)
# Access the target blogger page
# e.g. https://www.douyin.com/user/MS4wLjABAAAAnq8nmb35fUqerHx54jlTx76AEkfq-sMD3cj7QdgsOiM
driver.get(target)
# Wait for the elements of class='e6wsjNLL' and class='niBfRBgX' to finish loading respectively before continuing execution
# (just wait for ul.e6wsjNLL to finish loading)
# WebDriverWait(driver, 6) sets the maximum wait time to 6 seconds.
WebDriverWait(driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'e6wsjNLL')))
WebDriverWait(driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'niBfRBgX'))))
# Execute the script in the browser, scroll to the bottom of the page, potentially showing more entries
driver.execute_script('document.querySelector(".wcHSRAj6").scrollIntoView()')
sleep(1)
# Use [beautifulsoup](/search?q=beautifulsoup) to parse the page source code
html = BeautifulSoup(driver.page_source, 'lxml')
# Close the driver
driver.quit()
# Get the list of works
ul = html.find(class_='e6wsjNLL')
# Get each work
lis = ul.findAll(class_='niBfRBgX')
2. Before entering the work page, determine whether the work is a video work or a graphic work.
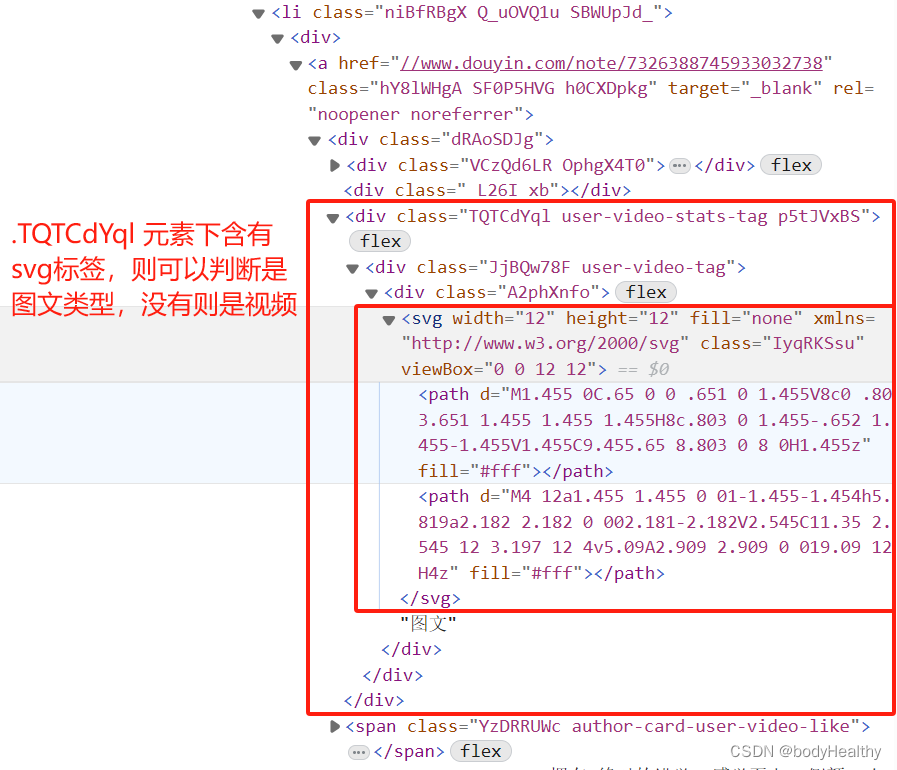
element_a = li.find('a')
# If an element with class = 'TQTCdYql' can be found under the a tag.
# is_pictures = element_a.find(class = 'TQTCdYql'), then the work is a graphic, if not (then None), then the work is a video
is_pictures = element_a.find(class_='TQTCdYql')
if (not is_pictures) or (not is_pictures.svg).
# video artwork
pass
else.
# Pictures
pass
3. Enter the video works page and obtain the video
# Spliced Works Address
href = f'https://www.douyin.com{element_a["href"]}'
# Use webdriver to access the artwork page
temp_driver = webdriver.Firefox(options=firefox_options)
temp_driver.set_page_load_timeout(6)
temp_driver.get(href)
# Wait for the element class='D8UdT9V8' to be displayed before executing (the content of this element is the release date of the work)
WebDriverWait(temp_driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'D8UdT9V8'))))
html_v = BeautifulSoup(temp_driver.page_source, 'lxml')
temp_driver.quit()
# Get the publish time of the work
publish_time = html_v.find(class_='D8UdT9V8').string[5:]
video = html_v.find(class_='xg-video-container').video
source = video.find('source')
# Create a folder for the work (one folder for each work)
# Name the folder after the release date of the work plus the type of the work
path = create_dir(f'{publish_time}_video')
# Download the work
download_works(path, f'{get_current_time()}.mp4', f'https:{source["src"]}')
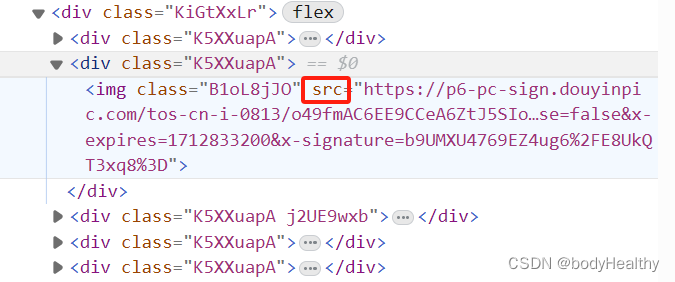
4. Enter the graphic works page to obtain pictures

# Splice Works page address
href = f'https:{element_a["href"]}'
# Use webdriver to access the artwork page
temp_driver = webdriver.Firefox(options=firefox_options)
temp_driver.set_page_load_timeout(6)
temp_driver.get(href)
# Wait for the tab containing the time the work was published to finish loading
WebDriverWait(temp_driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'YWeXsAGK')))
# Get the source code of the current page, close the webdriver and leave it to beautifulsoup
# (The rest of the task can be accomplished by continuing to use webdriver)
html_p = BeautifulSoup(temp_driver.page_source, 'lxml')
temp_driver.quit()
# Get the publish time of the entry
publish_time = f'{html_p.find(class_="YWeXsAGK")}'[-23:-7]
# List of images
img_ul = html_p.find(class_='KiGtXxLr')
imgs = img_ul.findAll('img')
# Create a folder for the work, in terms of when the work was published + type of work + number of images (if it's an image type work)
path = create_dir(f'{publish_time}_pictures_{len(imgs)}')
# Iterate over the images, get the url and then download them
for img in imgs.
download_works(path, f'{get_current_time()}.webp', f'{img["src"]}')
5. Complete reference code
# -*- coding: utf-8 -*-
import threading,requests,os,zipfile
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from pyvirtualdisplay import Display
from time import sleep
from bs4 import BeautifulSoup
from selenium.common.exceptions import WebDriverException
display = Display(visible=0, size=(1980, 1440))
display.start()
firefox_options = Options()
firefox_options.headless = True
firefox_options.binary_location = '/home/lighthouse/firefox/firefox'
# Get the current time
def get_current_time():
now = datetime.now()
format_time = now.strftime("_%Y-%m-%d__%H-%M-%S-%f__")
return format_time
# Set a root path where the work files and log files are kept
ABS_PATH = f'/home/resources/{get_current_time()}'
# Create a directory, dir_name is the release time of the work, in the format: 2024-02-26 16:59, which needs to be processed
def create_dir(dir_name).
dir_name = dir_name.replace(' ', '-').replace(':', '-')
path = f'{ABS_PATH}/{dir_name}'
try.
os.makedirs(path)
except FileExistsError: print(f'{ABS_PATH}/{dir_name}')
print(f'Attempt to create existing file, failed ({path})')
print(f'Attempt to create existing file, failed ({path})')
print(f'Attempt to create existing file failed ({path})') else: print(f'Creating directory succeeded {path}')
finally: return path
return path
# download Directory name, naming of the current file, address of the download
def download_works(dir_name, work_name, src):
response = requests.get(src, stream=True)
if response.status_code == 200: with open(f'{dir_name, work_name, src)
with open(f'{dir_name}/{work_name}', mode='wb') as f: for chunk in response.iterator: if response.status_code == 200.
for chunk in response.iter_content(1024): f.write(chunk): f.write(chunk)
f.write(chunk)
# Determine if a work has been downloaded
def test_work_exist(dir_name):: dir_name = dir_name.
dir_name = dir_name.replace(' ', '-').replace(':', '-')
path = f'{ABS_PATH}/{dir_name}'
if os.path.exists(path) and os.path.isdir(path): if os.listdir(path): if os.listdir(path)
if os.path.isdir(path): if os.listdir(path).
if os.listdir(path): if os.listdir(path): return True
if os.listdir(path): return True
def get_all_works(target): if os.path.exists(path) and os.path.
try: driver = webdriver.
driver = webdriver.Firefox(options=firefox_options)
driver.set_page_load_timeout(6)
# Target blogger page
driver.get(target)
WebDriverWait(driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'e6wsjNLL')))
WebDriverWait(driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'niBfRBgX')))
driver.execute_script('document.querySelector(".wcHSRAj6").scrollIntoView()')
sleep(1)
html = BeautifulSoup(driver.page_source, 'lxml')
driver.quit()
# List of works
ul = html.find(class_='e6wsjNLL')
# Each work
lis = ul.findAll(class_='niBfRBgX')
for li in lis.
element_a = li.find('a')
is_pictures = element_a.find(class_='TQTCdYql')
if (not is_pictures) or (not is_pictures.svg):: href = f'{eql')
href = f'https://www.douyin.com{element_a["href"]}'
temp_driver = webdriver.Firefox(options=firefox_options)
temp_driver.set_page_load_timeout(6)
temp_driver.get(href)
WebDriverWait(temp_driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'D8UdT9V8')))
# Not required, webdriver can handle the rest of the content
html_v = BeautifulSoup(temp_driver.page_source, 'lxml')
temp_driver.quit()
# Get the publish time of the entry
publish_time = html_v.find(class_='D8UdT9V8').string[5:]
# if test_work_exist(f'{publish_time}_video').
# continue
video = html_v.find(class_='xg-video-container').video
source = video.find('source')
# Create a folder for this work
path = create_dir(f'{publish_time}_video')
# Download the work
download_works(path, f'{get_current_time()}.mp4', f'https:{source["src"]}')
else.
href = f'https:{element_a["href"]}')
temp_driver = webdriver.Firefox(options=firefox_options)
temp_driver.set_page_load_timeout(6)
temp_driver.get(href)
WebDriverWait(temp_driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'YWeXsAGK')))
# Using beautifulsoup is not required
html_p = BeautifulSoup(temp_driver.page_source, 'lxml')
temp_driver.quit()
publish_time = f'{html_p.find(class_="YWeXsAGK")}'[-23:-7]
# List of images
img_ul = html_p.find(class_='KiGtXxLr')
imgs = img_ul.findAll('img')
# if test_work_exist(f'{publish_time}_pictures_{len(imgs)}'):: # continue
# continue
path = create_dir(f'{publish_time}_pictures_{len(imgs)}')
for img in imgs: # continue
download_works(path, f'{get_current_time()}.webp', f'{img["src"]}')
display.stop()
print('##### finish #####')
except WebDriverException as e.
print(f "WebDriverException caught: {e}")
except Exception as err: print("Caught WebDriverException: {e}")
print("Caught other error get_all_works end")
print(err)
finally: driver.quit()
driver.quit()
display.stop()
# Zip the directory
def zipdir(path, ziph): # ziph is a zipfile.
# ziph is a zipfile.
ZipFile object for root, dirs, files in os.walk(path): for file in files: # zipdir(path, ziph): # zipfile.
for file in files: # ziph is a zipfile.
ziph.write(os.path.join(root, file), os.path.relpath(path)): # ziph is a zipfile.
os.path.relpath(os.path.join(root, file), os.path.join(path, '...'))))
def dy_download_all(target_url).
get_all_works(target_url)
directory_to_zip = ABS_PATH # directory path
output_filename = f'{ABS_PATH}.zip' # output ZIP file name
with zipfile.ZipFile(output_filename, 'w', zipfile.ZIP_DEFLATED) as zipf:
zipdir(directory_to_zip, zipf)
return f'{ABS_PATH}.zip' # return download address
if __name__ == '__main__'.
# Simple test
url = input('Please enter the url of the blogger's homepage:')
path = dy_download_all(url)
print('Download complete')
print(f'address: {path}')
Test Results:

6. A way to obtain all works
The above operations are performed without logging in. Even if the page is scrolled through the operation in webdriver, only a limited number of works can be obtained, about 20 items. Come up with a solution to this.
Visit the target blogger's page in logged-in status (or with cookies local storage, etc.), scroll to the bottom of the work, and then execute the JavaScript script in the console to obtain the information of all works (here, the work link and work type), and then write out to a text file.
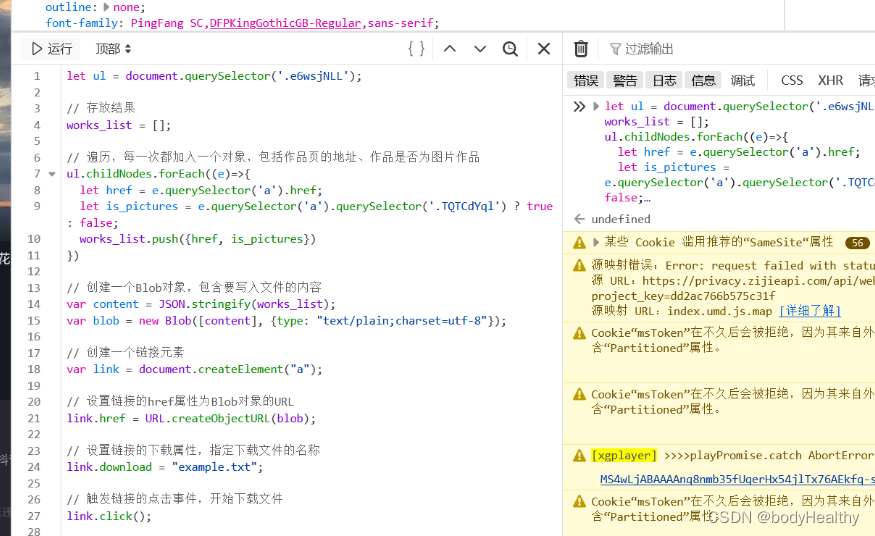
JavaScript code:
let ul = document.querySelector('.e6wsjNLL');
// Store the results
works_list = [];
// Iterate through, adding one object at a time, including the address of the works page and whether the works are images or not
ul.childNodes.forEach((e) => {
let href = e.querySelector('a').href;
let is_pictures = e.querySelector('a').querySelector('.TQTCdYql') ? true : false;
works_list.push({href, is_pictures})
})
// Create a Blob object containing the content to be written to the file
var content = JSON.stringify(works_list);
var blob = new Blob([content], {type: "text/plain;charset=utf-8"});
// Create a link element
var link = document.createElement("a"); var link = document.createElement("a"); // Set the href attribute of the link.
// Set the href attribute of the link to the URL of the Blob object
link.href = URL.createObjectURL(blob); // Set the link's download attribute.
// Set the link's download property to specify the name of the file to download
link.download = "example.txt"; // Set the link's download property, specifying the name of the file to download.
// Trigger a click event on the link to start downloading the file
link.click();
Write the result:
Each element in the list is an object, href is the address of the work, and is_pictures uses a boolean value to indicate whether the work is a picture work.
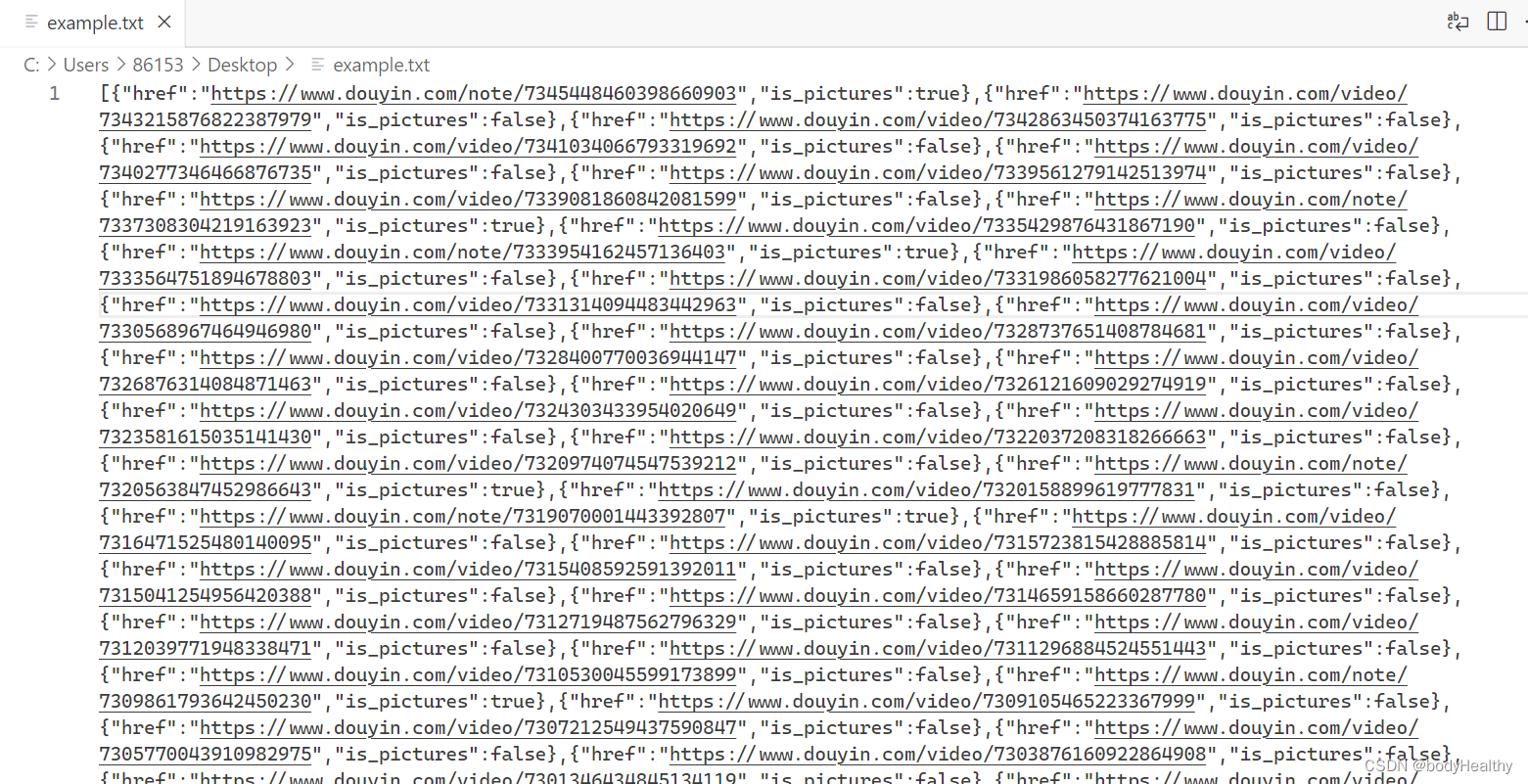
Then read the file in python, use json parsing, convert it into a dictionary list, traverse the list, and process each dictionary (that is, each work).
Sample code:
under win environment
import json
import threading,requests,os
from bs4 import BeautifulSoup
from seleniumwire import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
from datetime import datetime
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
# Get the current time
def get_current_time():
now = datetime.now()
format_time = now.strftime("_%Y-%m-%d__%H-%M-%S-%f__")
return format_time
# Set a root path where the work files and log files are kept
ABS_PATH = f'F:\\{get_current_time()}'
# Create a directory, dir_name is the release time of the work, format: 2024-02-26 16:59, need to be processed
def create_dir(dir_name).
dir_name = dir_name.replace(' ', '-').replace(':', '-')
path = f'{ABS_PATH}/{dir_name}'
try.
os.makedirs(path)
except FileExistsError: print(f'{ABS_PATH}/{dir_name}')
print(f'Attempt to create existing file, failed ({path})')
print(f'Attempt to create existing file, failed ({path})')
print(f'Attempt to create existing file failed ({path})') else: print(f'Creating directory succeeded {path}')
finally: return path
return path
# download Directory name, naming of the current file, address of the download
def download_works(dir_name, work_name, src):
response = requests.get(src, stream=True)
if response.status_code == 200: with open(f'{dir_name, work_name, src)
with open(f'{dir_name}/{work_name}', mode='wb') as f: for chunk in response.iterator: if response.status_code == 200.
for chunk in response.iter_content(1024): f.write(chunk): f.write(chunk)
f.write(chunk)
# Determine if the work has been downloaded
def test_work_exist(dir_name):
dir_name = dir_name.replace(' ', '-').replace(':', '-')
path = f'{ABS_PATH}/{dir_name}'
if os.path.exists(path) and os.path.isdir(path):
if os.listdir(path):
return True
return False
# Download a work
def thread_task(ul):
for item in ul.
href = item['href']
is_pictures = item['is_pictures']
if is_pictures: temp_driver = webdriver
temp_driver = webdriver.Chrome()
temp_driver.set_page_load_timeout(6)
temp_driver.get(href)
WebDriverWait(temp_driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'YWeXsAGK')))
# Using beautifulsoup is not required
html_p = BeautifulSoup(temp_driver.page_source, 'lxml')
temp_driver.quit()
publish_time = f'{html_p.find(class_="YWeXsAGK")}'[-23:-7]
# List of images
img_ul = html_p.find(class_='KiGtXxLr')
imgs = img_ul.findAll('img')
# if test_work_exist(f'{publish_time}_pictures_{len(imgs)}'):: # continue
# continue
path = create_dir(f'{publish_time}_pictures_{len(imgs)}')
for img in imgs: # continue
download_works(path, f'{get_current_time()}.webp', f'{img["src"]}')
else.
temp_driver = webdriver.Chrome()
temp_driver.set_page_load_timeout(6)
temp_driver.get(href)
WebDriverWait(temp_driver, 6).until(EC.presence_of_element_located((By.CLASS_NAME, 'D8UdT9V8')))
# Not required, webdriver can handle the rest of the content
html_v = BeautifulSoup(temp_driver.page_source, 'lxml')
temp_driver.quit()
# Get the publish time of the entry
publish_time = html_v.find(class_='D8UdT9V8').string[5:]
# if test_work_exist(f'{publish_time}_video').
# continue
video = html_v.find(class_='xg-video-container').video
source = video.find('source')
# Create a folder for this work
path = create_dir(f'{publish_time}_video')
# Download the work
download_works(path, f'{get_current_time()}.mp4', f'https:{source["src"]}')
if __name__ == '__main__'.
content = ''
# Read in the artwork link file externally
with open('... /abc.txt', mode='r', encoding='utf-8') as f.
content = json.load(f)
length = len(content)
if length <= 3 : thread_task(content)
thread_task(content)
else.
# split into three threads
ul = [content[0: int(length / 3) + 1], content[int(length / 3) + 1: int(length / 3) * 2 + 1], content[int(length / 3) * 2 + 1: length], content[int(length / 3) * 2 + 1: length], content[int(length / 3) * 2 + 1: length], content[int(length / 3) * 2 + 1: length].
content[int(length / 3) * 2 + 1: length]]
for child_ul in ul.
thread = threading.Thread(target=thread_task, args=(child_ul,))
thread.start()
*** Translated with www.DeepL.com/Translator (free version) ***