In-depth analysis of real-time data warehouse Doris: introduction, architecture analysis, application scenarios and data division details
In-depth analysis of real-time data warehouse Doris: introduction, architecture analysis, application scenarios and data division details

Code to thirty-five: personal homepage
There are poems and paintings in my heart, I dance with codes on my fingertips, I see the world with my eyes, and I walk across thousands of mountains, this world is worth it!
Doris is a high-performance, open source, real-time analysis data warehouse, designed to provide users with millisecond-level query response, high concurrency, high availability, and easy-to-expand OLAP solutions. It integrates MPP (massive parallel processing) architecture and distributed storage, supports PB-level data storage and analysis, and is an ideal real-time data warehouse choice in big data scenarios.
Table of contents
-
- 1. Introduction to Doris
- 2. Usage scenarios
-
- 2.1 Report analysis
- 2.2 Ad-hoc Query
- 2.3 Data warehouse construction
- 2.4 Data Lake Federated Query
- 3. Technical Overview
- 4. Data partitioning
-
- 4.1 Basic concepts
- 4.2 Data partitioning
1. Introduction to Doris
Apache Doris is a high-performance, real-time analytical database based on the MPP architecture. It is well known for its extremely fast and easy-to-use features. It only needs sub-second response time to return query results for massive data. It can not only support high concurrency Point query scenarios can also support high-throughput complex analysis scenarios. Based on this, Apache Doris can better meet usage scenarios such as report analysis, ad hoc query, unified data warehouse construction, data lake federated query acceleration, etc. Users can build user behavior analysis, AB experiment platform, log retrieval analysis, user Applications such as portrait analysis and order analysis.
Apache Doris was first born as a Palo project in Baidu's advertising reporting business. It was officially open sourced in 2017. In July 2018, it was donated to the Apache Foundation for incubation by Baidu. It was then incubated and developed by members of the incubator project management committee under the guidance of Apache mentors. operations. Currently, the Apache Doris community has gathered more than 600 contributors from hundreds of companies in different industries, and the number of monthly active contributors exceeds 120. In June 2022, Apache Doris successfully graduated from the Apache Incubator and officially became an Apache Top-Level Project (TLP)
Apache Doris now has a wide range of user groups in China and even around the world. Up to now, Apache Doris has been used in the production environments of more than 4,000 companies around the world. Among the top 50 Internet companies in China by market capitalization or valuation, More than 80% use Apache Doris for a long time, including Baidu, Meituan, Xiaomi, JD.com, ByteDance, Tencent, NetEase, Kuaishou, Weibo, Shell, etc. At the same time, it also has rich applications in some traditional industries such as finance, energy, manufacturing, telecommunications and other fields.
2. Usage scenarios
As shown in the figure below, after various data integration and processing, the data source is usually stored in the real-time data warehouse Doris and offline lake warehouse (Hive, Iceberg, Hudi). Apache Doris is widely used in the following scenarios. Image description
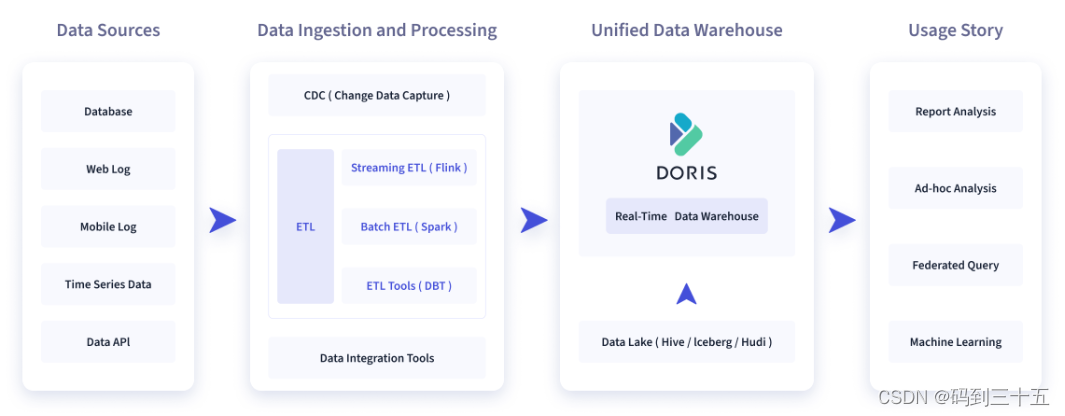
2.1 Report analysis
- Real-time dashboards
- Reports for internal analysts and managers
- Highly concurrent report analysis for users or customers (Customer Facing Analytics). For example, site analysis for website owners and advertising reports for advertisers usually require thousands of QPS for concurrency, and query latency requires millisecond-level response. JD.com, a well-known e-commerce company, uses Apache Doris in advertising reports, writing 10 billion rows of data every day, with tens of thousands of concurrent queries per QPS, and the 99th percentile query delay is 150ms.
2.2 Ad-hoc Query
Self-service analysis for analysts, the query mode is not fixed, and requires high throughput. Xiaomi has built a growth analysis platform (Growing Analytics, GA) based on Doris, which uses user behavior data to conduct business growth analysis. The average query delay is 10s, the 95th percentile query delay is within 30s, and the daily SQL query volume is tens of thousands. strip.
2.3 Data warehouse construction
One platform meets the unified data warehouse construction needs and simplifies the cumbersome big data software stack. The unified data warehouse built by Haidilao based on Doris has replaced the old architecture composed of Spark, Hive, Kudu, Hbase, and Phoenix, and the architecture has been greatly simplified.

2.4 Data Lake Federated Query
Through federated analysis of data in Hive, Iceberg, and Hudi through external appearance, query performance is greatly improved while avoiding data copying.
3. Technical Overview
The overall architecture of Doris is shown in the figure below. The Doris architecture is very simple, with only two types of processes.
-
Frontend (FE) is responsible for user request access, query resolution planning, metadata management, and node management.
-
Backend (BE) , mainly responsible for data storage, query plan execution.
Both types of processes are horizontally scalable, with a single cluster supporting hundreds of machines and tens of petabytes of storage capacity. And these two types of processes through the consistency agreement to ensure the high availability of services and high reliability of data. This highly integrated architecture design greatly reduces the operation and maintenance costs of a distributed system.
The design of this highly integrated architecture greatly reduces the operation and maintenance costs of a distributed system. In-depth analysis of real-time data warehouse Doris: introduction, architecture analysis, application scenarios and data division details
In terms of User Interface, Doris adopts MySQL protocol, which is highly compatible with MySQL syntax and supports standard SQL. Users can access Doris through all kinds of client tools and support seamless connection with BI tools. Doris currently supports a variety of mainstream BI products, including but not limited to SmartBI, DataEase, FineBI, Tableau, Power BI, SuperSet, etc., as long as the BI tools that support the MySQL protocol, Doris can be used as a data source to provide query support.
In terms of storage engine, Doris uses columnar storage, encoding and compression and reading of data by columns, which can achieve a very high compression ratio, and at the same time reduce a large number of non-relevant data scanning, so as to make more effective use of IO and CPU resources.
Doris also supports a rich set of index structures to reduce data scanning:
-
Sorted Compound Key Index, you can specify up to three columns to form a composite sort key , through the index , you can effectively carry out data cropping , so as to better support the high concurrency reporting scenarios
-
Min/Max: effective filtering of numerical types of equal value and range queries
-
Bloom Filter: very effective in filtering and cropping equal values of high cardinality columns.
-
Invert Index: enables fast retrieval of any field.
In terms of storage models, Doris supports a variety of storage models, optimized for different scenarios:
-
Aggregate Key model: the Value columns of the same Key are merged, and the performance is greatly improved by early aggregation.
-
Unique Key model: Key uniqueness, data coverage of the same key, row-level data updates.
-
Duplicate Key Model: Detailed data model to satisfy the detailed storage of fact table.
Doris also supports strongly consistent Materialized Views, where updates and selections of materialized views are performed automatically within the system, eliminating the need for users to manually select them, thus significantly reducing the cost of maintaining materialized views.
In terms of query engine, Doris adopts the MPP model, with both inter-node and intra-node parallel execution, and also supports distributed Shuffle Join of multiple large tables, which can better cope with complex queries.
In-depth analysis of real-time analysis of the MPP model. In-depth analysis of real-time data warehouse Doris: introduction, architecture analysis, application scenarios and data division details
Doris query engine is a vectorized query engine, all memory structures can be laid out in columnar fashion, which can achieve the effect of significantly reducing virtual function calls, improving the Cache hit rate, and efficiently utilizing SIMD instructions. ** In the wide-table aggregation scenario, the performance is 5-10 times that of a non-quantized engine. **
In-depth analysis of real-time analytics. In-depth analysis of real-time data warehouse Doris: introduction, architecture analysis, application scenarios and data division details
Doris uses Adaptive Query Execution technology to dynamically adjust the execution plan based on Runtime Statistics, such as Runtime Filter technology that generates a Filter at runtime and pushes it to the Probe side, and automatically penetrates the Filter to the Probe side. Doris Runtime Filter supports In/Min/Max/Bloom Filter.
Doris Runtime Filter supports In/Min/Max/Bloom Filter. Doris uses a combination of CBO and RBO optimization strategy for optimizer, RBO supports constant folding, subquery rewriting, predicate push down, etc. CBO supports Join Reorder, etc. Currently, CBO is still under continuous optimization, which is mainly focusing on more accurate statistics collection and derivation, and more accurate estimation of cost model.
4. Data segmentation
4.1 Basic Concepts
In Doris, data are logically described in the form of tables (Table).
Row & Column.
A table consists of Row and Column:
-
Row: i.e. a row of data for the user;
-
Column: used to describe the different fields in a row of data.
Column can be divided into two categories: Key and Value. from the business point of view, Key and Value can correspond to dimension columns and indicator columns respectively. the key column of Doris is the column specified in the table building statement, and the keywords 'unique key' or 'aggregate key' or 'aggregate key' in the table building statement can be used. The columns after the keywords 'unique key' or 'aggregate key' or 'duplicate key' in the table building statement are the key columns, and the rest of the columns are the value columns. From the point of view of the aggregation model, rows with the same key column will be aggregated into one row. The aggregation method of Value column is specified by the user when creating the table. For more information about the aggregation model, see Doris Data Model.
Tablet & Partition
In the Doris storage engine, user data is horizontally partitioned into tablets, also known as buckets. Each Tablet contains several rows of data. There is no intersection of data between Tablets and they are physically stored independently.
Multiple Tablets logically belong to different partitions. A Tablet belongs to only one Partition, and a Partition contains several Tablets, and because the Tablets are physically stored independently, they can be considered to be physically independent of the Partition as well.A Tablet is the smallest physical storage unit to which data can be moved, copied, and so on.
Tablet is the smallest physical storage unit for data movement, copying, etc. Several Partitions form a Table, and a Partition can be regarded as the smallest logical management unit. Data can be imported or deleted only for one Partition.
4.2 Data Partitioning
We illustrate Doris data partitioning with a table building operation.
Doris table building is a synchronized command, which returns the result when the SQL execution is finished, and the success of the command means the table building is successful. You can refer to CREATE TABLE for specific syntax of table creation, or you can also see more help through HELP CREATE TABLE;.
This subsection introduces the table creation method of Doris through an example.
-- Range Partition
CREATE TABLE IF NOT EXISTS example_db.example_range_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "User id", `date` DATE NOT NULL COMMENT "Date and time of data feed", `date` DATE NOT NULL COMMENT "Date and time of data feed".
`date` DATE NOT NULL COMMENT "Date and time of the data entry", `timestamp` DATE NOT NULL COMMENT
`timestamp` DATETIME NOT NULL COMMENT "The timestamp of the data infusion", `city` VARCHARCHARCHARCHARCHARCHARCHARCHARCHARCHARCHARCHARCHARCHARCHARGE
`city` VARCHAR(20) COMMENT "The city where the user is located", `age` SMALLINT COMMENT "The city where the user is located", `age` SMALLINT COMMENT
`age` SMALLINT COMMENT "The age of the user", `sex` TINYINT COMMENT
`sex` TINYINT COMMENT "The gender of the user", `last_visit_country
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "User's last visit date",
`cost` BIGINT SUM DEFAULT "0" COMMENT "Total consumption of the user",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "Maximum user dwell time",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "Minimum user dwell time"
)
ENGINE=OLAP
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY RANGE(`date`)
(
PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),
PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),
PARTITION `p201703` VALUES LESS THAN ("2017-04-01")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
(
"replication_num" = "3",
"storage_medium" = "SSD",
"storage_cooldown_time" = "2018-01-01 12:00:00"
);
-- List Partition
CREATE TABLE IF NOT EXISTS example_db.example_list_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "user_id", `date` DATE NOT NULL COMMENT "user_id", -- list_list_tbl (
`date` DATE NOT NULL COMMENT "Date and time of the data entry", `timestamp` DATE NOT NULL COMMENT
`timestamp` DATETIME NOT NULL COMMENT "The timestamp of the data infusion", `city` VARCHARCHARCHARCHARCHARCHARCHARCHARCHARCHARCHARCHARCHARCHARCHARGE
`city` VARCHAR(20) NOT NULL COMMENT "The city where the user is located", `age` SMALLINT COMMENT "The city where the user is located", `age` SMALLINT COMMENT
`age` SMALLINT COMMENT "Age of the user", `sex` TINYINT COMMENT
`sex` TINYINT COMMENT "The gender of the user", `last_visit_city
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "User's last visit date",
`cost` BIGINT SUM DEFAULT "0" COMMENT "Total consumption of the user",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "Maximum user dwell time",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "Minimum user dwell time"
)
ENGINE=olap
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY LIST(`city`)
(
PARTITION `p_cn` VALUES IN ("Beijing", "Shanghai", "Hong Kong"),
PARTITION `p_jp` VALUES IN ("Tokyo")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
(
"replication_num" = "3",
"storage_medium" = "SSD",
"storage_cooldown_time" = "2018-01-01 12:00:00"
).
*** Translated with www.DeepL.com/Translator (free version) ***
Column Definition
We will only use the AGGREGATE KEY data model as an example here. For more data models, see Doris Data Models.
The basic types of columns can be seen by executing HELP CREATE TABLE; in mysql-client.
In the AGGREGATE KEY data model, all columns that do not specify an aggregation method (SUM, REPLACE, MAX, MIN) are considered Key columns. The rest are Value columns.
The following suggestions can be used to define columns:
** The Key column must come before all Value columns. ** Choose integer type as much as possible. Because the calculation and searching efficiency of integer type is much higher than that of string.
- For integer types of different lengths, follow the principle of "enough is enough".
- For the length of VARCHAR and STRING types, follow the principle that enough is enough.
**Partitioning and Bucketing
Doris supports two levels of data partitioning. The first layer is Partition, which supports Range and List. The second layer is Bucket (Tablet), which supports Hash and Random.
You can also use only one layer of partitioning, if you don't write a statement about partitioning when building a table, Doris will generate a default partition, which is transparent to the user. When using one layer of partitioning, only Bucket partitioning is supported. Here we introduce the partition and bucket respectively:
Partition
- Partition column can specify one or more columns, the partition column must be a KEY column.
- Range Partition supports the use of NULL partitioned columns when allowPartitionColumnNullable is true. list Partition always does not support NULL partitioned columns.
- Regardless of the type of partition column, double quotes are required when writing partition values.
- There is no theoretical upper limit to the number of partitions.
- When you do not use Partition to build a table, the system will automatically generate a Partition with the same name as the table name and full value range, which is not visible to the user and cannot be deleted or modified. This partition is not visible to the user and cannot be deleted or modified. * You cannot add partitions with overlapping ranges when creating partitions.
Range Partition **Partition columns are usually time columns.
-
Partition columns are usually time columns to make it easier to manage old and new data.
-
Range Partition supported column types: [DATE,DATETIME,TINYINT,SMALLINT,INT,BIGINT,LARGEINT]
-
Partition supports specifying only the upper bound via VALUES LESS THAN (...), the system will take the upper bound of the previous partition as the lower bound of the partition, generating a left-closed-right-open interval. VALUES [...] is also supported to generate a left-closed-right-open interval by specifying upper and lower bounds.
-
Version 1.2.0 also supports generating a left-closed-right-open interval by
FROM(...)'. TO (...) INTERVAL ...to create partitions in bulk.
Specifying both upper and lower bounds with VALUES (...) is easier to understand. Here is an example of how the range of partitions changes when the VALUES LESS THAN (...) statement is used to add or delete partitions:
As in the above example_range_tbl example, when the table is built, the following three partitions will be automatically generated:
p201701: (MIN_VALUE, 2017-02-01)
p201702: (2017-02-01, 2017-03-01)
p201703: (2017-03-01, 2017-04-01)
When we add a partition p201705 VALUES LESS THAN ("2017-06-01"), the partition results are as follows:
p201701: (MIN_VALUE, 2017-02-01)
p201702: (2017-02-01, 2017-03-01)
p201703: (2017-03-01, 2017-04-01)
p201705: (2017-04-01, 2017-06-01)
At this point we delete partition p201703, then the partition result is as follows:
p201701: (MIN_VALUE, 2017-02-01)
p201702: (2017-02-01, 2017-03-01)
p201705: (2017-04-01, 2017-06-01)
Notice that the partition ranges of p201702 and p201705 have not changed, and between these two partitions, there is a hole:(2017-03-01,2017-04-01). That is, if the imported data range is within this empty hole, it cannot be imported.
Continue to delete partition p201702, the partition result is as follows:
p201701: (MIN_VALUE, 2017-02-01)
p201705: (2017-04-01, 2017-06-01)
The void range becomes: (2017-02-01, 2017-04-01)
Now add a partition p201702new VALUES LESS THAN ("2017-03-01") and the partition result is as follows:
p201701: (MIN_VALUE, 2017-02-01)
p201702new: (2017-02-01, 2017-03-01)
p201705: (2017-04-01, 2017-06-01)
You can see that the void range is narrowed down to (2017-03-01, 2017-04-01)
Now delete partition p201701 and add partition p201612 VALUES LESS THAN ("2017-01-01") and the partition result is as follows:
p201612: [MIN_VALUE, 2017-01-01)
p201702new: [2017-02-01, 2017-03-01)
p201705: [2017-04-01, 2017-06-01)
I.e., a new void appears: (2017-01-01, 2017-02-01)
To summarize, the deletion of a partition does not change the extent of an already existing partition. Deletion of a partition may result in a void. When a partition is added via the VALUES LESS THAN statement, the lower bound of the partition follows the upper bound of the previous partition.
Range partitioning supports multi-column partitioning in addition to the single-column partitioning we saw above, as exemplified by the following:
PARTITION BY RANGE(`date`, `id`)
(
PARTITION `p201701_1000` VALUES LESS THAN ("2017-02-01", "1000"),
PARTITION `p201702_2000` VALUES LESS THAN ("2017-03-01", "2000"),
PARTITION `p201703_all` VALUES LESS THAN ("2017-04-01")
)
In the above example, we specify date(DATE type) and id(INT type) as the partition columns. The above example ends up with the following partition:
* p201701_1000: ((MIN_VALUE, MIN_VALUE), ("2017-02-01", "1000") )
* p201702_2000: (("2017-02-01", "1000"), ("2017-03-01", "2000") )
* p201703_all: (("2017-03-01", "2000"), ("2017-04-01", MIN_VALUE))
Note that the last partition user specifies only the partition value of the date column by default, so the partition value of the id column will be filled with MIN_VALUE by default. when the user inserts the data, the partition column values will be compared in order to get the corresponding partition. Examples are as follows:
* Data --> partitioning
* 2017-01-01, 200 --> p201701_1000
* 2017-01-01, 2000 --> p201701_1000
* 2017-02-01, 100 --> p201701_1000
* 2017-02-01, 2000 --> p201702_2000
* 2017-02-15, 5000 --> p201702_2000
* 2017-03-01, 2000 --> p201703_all
* 2017-03-10, 1 --> p201703_all
* 2017-04-01, 1000 --> Unable to import
* 2017-05-01, 1000 --> Unable to import
Range partitioning also supports batch partitioning, through the statement FROM ("2022-01-03") TO ("2022-01-06") INTERVAL 1 DAY batch to create a partition by day: 2022 -01-03 to 2022-01-06 (excluding 2022-01-06 day), the partition results are as follows:
p20220103: (2022-01-03, 2022-01-04) p20220104: (2022-01-04,
2022-01-05) p20220105: (2022-01-05, 2022-01-06)
List Partitions
The Partition column supports BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, DATE, DATETIME, CHAR, VARCHAR data types, and the partition value is an enumeration value. A partition can be hit only if the data is one of the enumerated values of the target partition.
Partition supports specifying the enumeration values for each partition by VALUES IN (...).
The following is an example of how a partition changes when you add or delete partitions.
As in the example_list_tbl example, when the table is built, the following three partitions will be created automatically:
p_cn: ("Beijing", "Shanghai", "Hong Kong") p_usa: ( "New York", "San
Francisco") p_jp: ("Tokyo")
When we add a partition p_uk VALUES IN ("London"), the partition results are as follows:
p_cn: ("Beijing", "Shanghai", "Hong Kong") p_usa: ( "New York", "San
Francisco") p_jp: ("Tokyo") p_uk: ("London")
When we delete the partition p_jp, the partition results are as follows:
p_cn: ("Beijing", "Shanghai", "Hong Kong") p_usa: ( "New York", "San
Francisco") p_uk: ("London")
List partition also supports multi-column partition, the example is as follows:
PARTITION BY LIST(
id,city) (
PARTITIONp1_cityVALUES IN ((“1”, “Beijing”), (“1”, “Shanghai”)),
PARTITIONp2_cityVALUES IN ((“2”, “Beijing”), (“2”, “Shanghai”)),
PARTITIONp3_cityVALUES IN ((“3”, “Beijing”), (“3”, “Shanghai”)) )
In the above example, we specify id(INT type) and city(VARCHAR type) as the partition columns. The above example ends up with the following partition:
- p1_city: [(“1”, “Beijing”), (“1”, “Shanghai”)]
- p2_city: [(“2”, “Beijing”), (“2”, “Shanghai”)]
- p3_city: [(“3”, “Beijing”), (“3”, “Shanghai”)]
When the user inserts data, the partition column values will be compared in order, and the corresponding partitions will eventually be obtained. Examples are as follows:
- Data—>Partition
- 1, Beijing —> p1_city
- 1, Shanghai —> p1_city
- 2, Shanghai —> p2_city
- 3, Beijing —> p3_city
- 1, Tianjin —> Unable to import
- 4, Beijing —> Unable to import
Bucket
-
If Partition is used, the DISTRIBUTED... statement describes the rules for dividing data within each partition. If Partition is not used, it describes the partition rules for the data of the entire table.
-
Bucketing columns can be multiple columns, Aggregate and Unique models must be Key columns, Duplicate models can be key columns and value columns. The bucketing column can be the same as the Partition column or different.
-
The selection of bucketing columns is a trade-off between query throughput and query concurrency:
- If you select multiple bucketing columns, the data is more evenly distributed. If a query condition does not contain equivalent conditions for all bucketed columns, the query will trigger simultaneous scanning of all buckets, so the query throughput will increase and the latency of a single query will decrease. This method is suitable for query scenarios with high throughput and low concurrency.
- If only one or a few bucketed columns are selected, the corresponding point query can trigger only one bucket scan. At this time, when multiple point queries are concurrent, these queries have a greater probability of triggering different bucket scans respectively, and the IO impact between each query is small (especially when different buckets are distributed on different disks), so this This method is suitable for high-concurrency point query scenarios.
-
AutoBucket: Calculate the number of buckets based on the amount of data. For partition tables, a bucket can be determined based on the data volume of historical partitions, the number of machines, and the number of disks.
-
The number of buckets is theoretically unlimited.
Suggestions on the number of Partitions and Buckets and the amount of data
- The total number of Tablets in a table is equal to (Partition num * Bucket num).
- The number of tablets for a table, without considering expansion, is recommended to be slightly more than the number of disks in the entire cluster.
Theoretically there is no upper or lower bound on the data volume of a single Tablet, but it is recommended to be in the range of 1G - 10G. If the data volume of a single tablet is too small, the aggregation effect of the data will be poor and the metadata management pressure will be high. If the amount of data is too large, it is not conducive to copy migration and completion, and will increase the cost of retrying failed Schema Change or Rollup operations (the granularity of failed retries for these operations is Tablet). - When the data volume principle and quantity principle of Tablet conflict, it is recommended to give priority to the data volume principle.
- When creating a table, the number of Buckets for each partition is specified uniformly. However, when adding partitions dynamically (ADD PARTITION), the number of Buckets for the new partition can be specified separately. You can use this function to conveniently deal with data shrinkage or expansion.
- Once the number of Buckets for a Partition is specified, it cannot be changed. Therefore, when determining the number of Buckets, cluster expansion needs to be considered in advance. For example, there are currently only 3 hosts, and each host has 1 disk. If the number of Buckets is only set to 3 or less, even if you add more machines later, the concurrency cannot be improved.
- To give some examples: Assume that there are 10 BEs and each BE has a disk. If the total size of a table is 500MB, you can consider 4-8 shards. 5GB: 8-16 shards. 50GB: 32 shards. 500GB: Recommended partitions, each partition size is about 50GB, and each partition has 16-32 shards. 5TB: Recommended partitions, each partition size is about 50GB, and each partition has 16-32 shards.
Note: The data volume of the table can be viewed through the SHOW DATA command. The result is divided by the number of copies, which is the data volume of the table.
About the settings and usage scenarios of Random Distribution
- If the OLAP table does not have an update type field, setting the data bucketing mode of the table to RANDOM can avoid serious data skew (when data is imported into the partition corresponding to the table, the data for each batch of a single import job will be randomly selected a tablet for writing).
- When the bucketing mode of the table is set to RANDOM, because there is no bucketing column, it is impossible to query only a few buckets based on the value of the bucketing column. When querying the table, all buckets that hit the partition will be scanned at the same time. This setting is suitable for aggregate query analysis of the entire table data but not for high-concurrency point queries.
- If the OLAP table is the data distribution of Random Distribution, then you can set the single-shard import mode (set load_to_single_tablet to true) when importing data. Then when importing a large amount of data, a task will write the data to the corresponding Only one shard will be written to the partition, which will improve the concurrency and throughput of data import, reduce write amplification problems caused by data import and compaction, and ensure the stability of the cluster.
Composite partitioning and single partitioning
Composite partition
- The first level is called Partition, that is, partition. Users can specify a certain dimension column as a partition column (currently only integer and time type columns are supported), and specify the value range of each partition.
- The second level is called Distribution, which is bucketing. Users can specify one or more dimension columns and the number of buckets to perform HASH distribution on the data, or set it to Random Distribution without specifying the bucketing column to perform random distribution on the data.
It is recommended to use composite partitions in the following scenarios:
- If there is a time dimension or similar dimensions with ordered values, such dimension columns can be used as partition columns. Partition granularity can be evaluated based on import frequency, partition data volume, etc.
- Historical data deletion requirements: If there is a need to delete historical data (for example, only the last N days of data will be retained). Using composite partitions, you can achieve your goal by deleting historical partitions. Data can also be deleted by sending a DELETE statement within the specified partition.
- Solve the problem of data skew: Each partition can independently specify the number of buckets. For example, if partitioning is by day, when the amount of data varies greatly from day to day, you can reasonably divide the data in different partitions by specifying the number of buckets for the partition. It is recommended to select a column with a high degree of differentiation for the bucket column.
- Users can also use single partitions instead of composite partitions. Then the data is only HASH distributed.
ENGINE
In this example, the type of ENGINE is olap , which is the default ENGINE type. In Doris, only this ENGINE type is responsible for data management and storage by Doris. Other ENGINE types, such as mysql, broker, es, etc., are essentially just mappings to tables in other external databases or systems to ensure that Doris can read these data. Doris itself does not create, manage or store any non-olap ENGINE type tables and data.
Others
IF NOT EXISTS means that if the table has not been created, create it. Note that this only determines whether the table name exists, and does not determine whether the newly created table structure is the same as the existing table structure. Therefore, if there is a table with the same name but is not homogeneous, the command will also return success, but it does not mean that a new table and new structure have been created.
Skills are renewed by sharing, and every time I gain new knowledge, my heart overflows with joy.
We sincerely invite you to follow the public account "Code 35." to obtain more technical information.